微调策略对比
NLP大作业,选择了一个关于模型微调的题目,浅学了一下模型的微调策略,在这里介绍两种策略:全量微调和LoRA。
why fine-tuing?
当大模型完成pretrain之后,它在各个方面都具备了一定的能力。但是比方说我想要提升模型在某一个方面的能力,例如代码能力,我就需要对模型进行微调,让模型的代码能力更加优秀。
LLM的背后是海量的参数,这些参数以矩阵的形式存储,我们在微调的时候,其实就是在改变某些参数。
为什么是“微调”,因为我们想要改变一小部分的参数,把模型的某些性能提上去,但不想要那些已经做的满意的性能变差,也就是不宜改变大量的参数。
全量微调
比方说有矩阵W: \[ W = \begin{pmatrix} W_{11} & W_{12} & \cdots & W_{1m} \\ W_{21} & W_{22} & \cdots & W_{2m} \\ \vdots & \vdots & \ddots & \vdots \\ W_{n1} & W_{n2} & \cdots & W_{nm} \end{pmatrix} \]
假设微调之后的结果是: \[ W' = \begin{pmatrix} W_{11} & W_{12} & \cdots & W_{1m} \\ W_{21} & W_{22} & \cdots & W_{2m} \\ \vdots & \vdots & \ddots & \vdots \\ W_{n1} & W'_{n2} & \cdots & W'_{nm} \end{pmatrix} \] 也就是说,只有两个参数有变动,其他的参数其实都没变化。即使是这样,我们也可以理解成,这整个矩阵加上了一个新的稀疏矩阵(很多0): \[ \Delta W = \begin{pmatrix} 0 & 0 & \cdots & 0 \\ 0 & 0 & \cdots & 0 \\ \vdots & \vdots & \ddots & \vdots \\ 0 & ∆W'_{n2} & \cdots & ∆W'_{nm} \end{pmatrix} \]
\[ W' = W + \Delta W \]
这就是全量微调,我们在该过程中其实对所有参数都进行了更新。很明显,该方法存在冗余计算问题,带来了大量的不必要的浪费。
LoRA微调策略
所以,未为了解决全量微调不必要的弊端,LoRA微调策略诞生了,它引入了低秩分解技术(其实就素线性代数哇)。
要求使用包含行间数学公式:线代及格的小伙伴们都知道,一个矩阵 $ A ^{100 × k} $ 和一个矩阵 $ B ^{k × 100}$ 相乘得到的矩阵是 $ W ^{100 × 100} $。
那么我们在全量微调中使用的增量矩阵 $ ∆ W $
也可以用同样的方式表示:
\[
\Delta W = A_{\Delta} B_{\Delta}
\] 也就是说: \[
W = W_0 + \Delta W = W_0 + A_{\Delta} B_{\Delta}
\]
基于这个思路,如果我们要更新的参数矩阵$ W ^{m × n} $非常大,但我们也使用两个小矩阵相乘,这样需要调整的参数量就降下来了。
\[ m \cdot n \gg m \cdot k + k \cdot n \quad (\text{where} \quad m, n \gg k) \]
这样大大减少了需要调整的参数量,并有效减少了计算复杂度,但是,这样的微调效果和全量微调的效果相比,会怎么样呢? (To be continued...)
记一次LlamaFactory微调失败的学习过程
我在使用LlamaFactory框架对deepseek-coder-6.7b-instruct进行sft指令微调的时候,我所使用的数据集一个80k一个260k,但是,我只跑了36分钟就跑完了。why?
经过查找,是在yaml文件中的配置出了问题: 1
2
3
4
5
6
7### dataset
dataset: Magicoder-OSS-Instruct-75K,ULtraInteract_sft
template: deepseekcoder
cutoff_len: 1024
max_samples: 1000
overwrite_cache: true
preprocessing_num_workers: 16max_samples设置成了1000,也就是对我所使用的每一个数据集,都仅仅使用了1000条数据,那么一共就使用了2000条数据而已,这速度当然没得说😂😂
理解下这些小项的意思:
template: 指代数据处理时一种特殊的格式,决定了如何把原始数据转换为模型可以接受的输入格式,包括一些special tokens等,根据supported-models找到自己模型对应的template,当然也可以在template.py中定义自己的template。cutoff_len: 定义文本最大长度是多少token,如果超过这个长度将会被截断(切记是token而不是词语数量)max_samples: 指在训练过程中最多使用的样本数(但在实际操作中发现其实是对每一个数据集所摘取的最大样本数)overwrite_cache: 是否覆盖之前的数据处理缓存。如果设置为true,则在处理数据时会重新生成缓存,不使用之前生成的缓存。preprocessing_num_workers: 数据预处理时使用的工作线程数,默认指定为 16 个并行的处理线程。
1 | |
logging_steps: 每隔10步记录一次日志信息,在log中体现如下:
save_steps: 每隔500步保存一下模型的checkpoint,那如果你的总共的step大于500,就会生成checkpoint-500,checkpoint-1000这样的文件夹,如果小于500,也会成成一个checkpoint-步数的文件夹,其实最终结果会保存两次。
1 | |
per_device_train_batch_size: 每个设备上一次处理的样本数量,称为批量大小。它决定了每次训练时每个设备上处理多少条数据。gradient_accumulation_steps: 模型在进行权重值的更新之前会累计8次的梯度。也就是说,经过8个批次的数据后模型才会更新模型的权重。num_train_epochs: 表示数据集被完整训练一次。每个epoch代表模型对整个训练数据集的完整处理。更多的epoch通常意味着更充分的训练,但过多的epoch可能导致过拟合lr_scheduler_type: 学习率调度器类型,在这里指定使用余弦退火调度(cosine learning rate scheduler),当然也有其他的学习率调度方式。在整个训练过程中,学习率会先快速下降,然后以更平缓的速度逐渐减少(类似于余弦函数1/4的下降趋势)。warmup_ratio: 学习率的预热比例,表示在训练开始时,前10%的训练步骤用于从0逐渐增大学习率到设定的值。学习率预热有助于稳定训练的早期阶段,避免学习率太大使得模型更新过快。这篇文章讲的不错~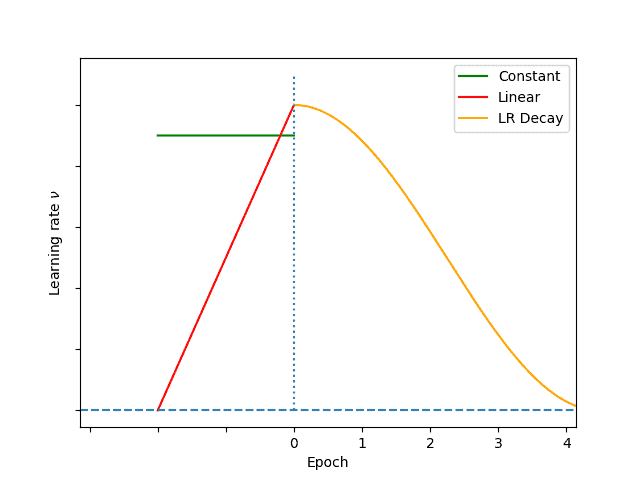
1 | |
val_size: 验证集的比例,表示从整个数据集中抽取 10% 作为验证集(validation set)。per_device_eval_batch_size: 每个设备用于评估时处理的样本数量。eval_strategy: 评估策略,表示评估是在训练过程中的固定步数之后进行(而不是每个epoch结束时)。eval_steps: 如果选择了按步评估策略(eval_strategy: steps),eval_steps决定了评估的频率。这个数值可以调节评估频次,较小的数值会更频繁地评估模型,但也会占用更多的时间,在本例中,如果总步数未达到500步,那么就在训练结束之后评估。